Prompt caching
Prompt caching is a powerful feature that helps you save credits by avoiding redundant processing of repeated prompt content. When you send similar requests-such as those with a consistent system prompt, long context, or shared data-the cached tokens from previous requests are reused instead of being re-tokenized and computed from scratch. This significantly reduces the cost of input tokens on follow-up requests, especially for long or repetitive prompts, while maintaining the same output quality.
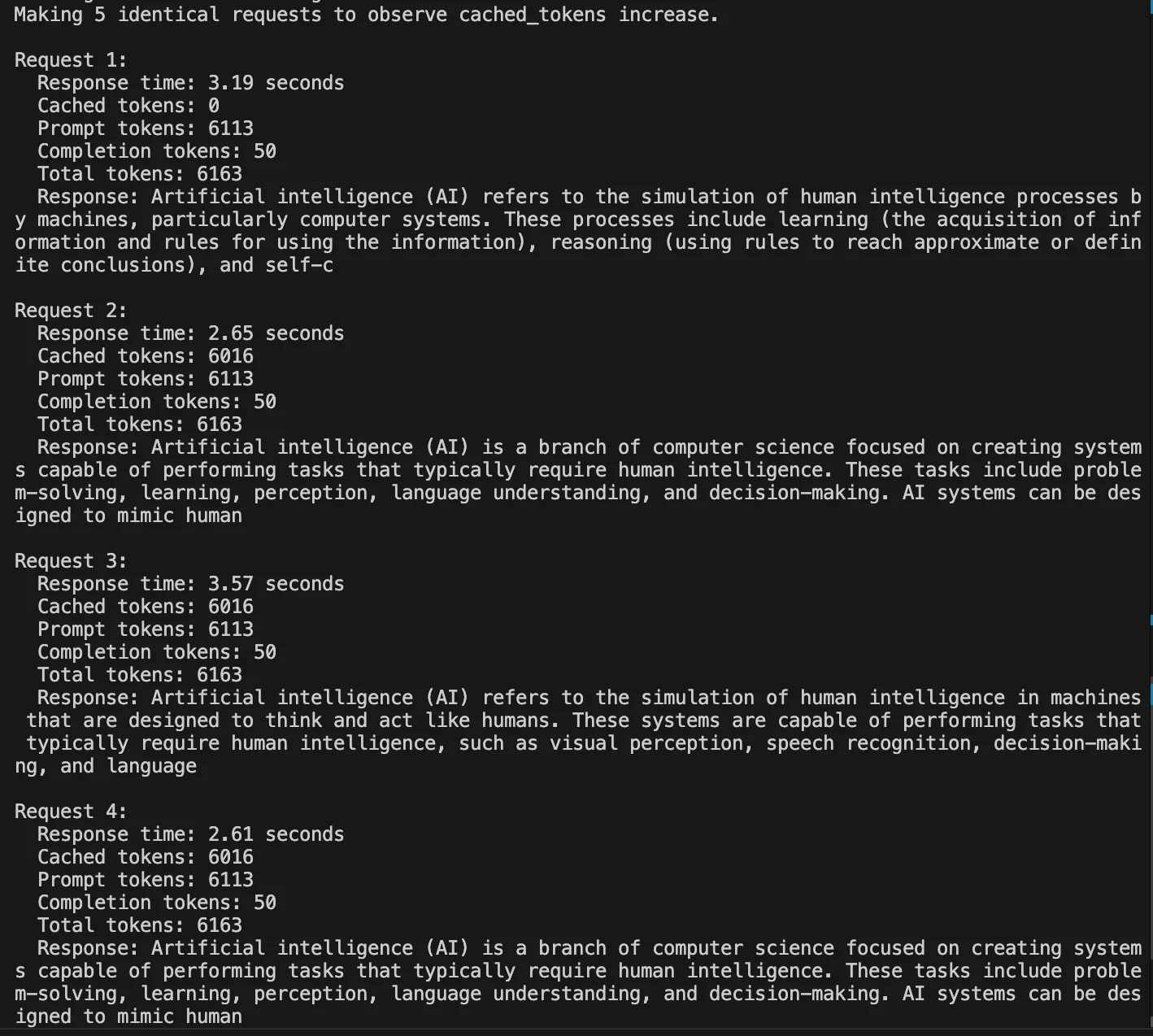
When using caching (whether automatically in supported models, or via the cache_control property), BlackBox will make a best-effort to continue routing to the same provider to make use of the warm cache. In the event that the provider with your cached prompt is not available, BlackBox will try the next-best provider.
Inspecting cache usage
To see how much caching saved on each generation, you can:
- Use
usage: {include: true}in your request to get the cache tokens at the end of the response.
The cache_discount field in the response body will tell you how much the response saved on cache usage. Some providers, like Anthropic, will have a negative discount on cache writes, but a positive discount (which reduces total cost) on cache reads.
OpenAI
Caching price changes:
- Cache writes: no cost
- Cache reads: (depending on the model) charged at 0.25x or 0.50x the price of the original input pricing
Click here to view OpenAI's cache pricing per model.
Prompt caching with OpenAI is automated and does not require any additional configuration. There is a minimum prompt size of 1024 tokens.
Click here to read more about OpenAI prompt caching and its limitation.
Grok
Caching price changes:
- Cache writes: no cost
- Cache reads: charged at {GROK_CACHE_READ_MULTIPLIER}x the price of the original input pricing
Click here to view Grok's cache pricing per model.
Prompt caching with Grok is automated and does not require any additional configuration.
Moonshot AI
Caching price changes:
- Cache writes: no cost
- Cache reads: charged at {MOONSHOT_CACHE_READ_MULTIPLIER}x the price of the original input pricing
Prompt caching with Moonshot AI is automated and does not require any additional configuration.
Click here to view Moonshot AI's caching documentation.
Groq
Caching price changes:
- Cache writes: no cost
- Cache reads: charged at {GROQ_CACHE_READ_MULTIPLIER}x the price of the original input pricing
Prompt caching with Groq is automated and does not require any additional configuration. Currently available on Kimi K2 models.
Click here to view Groq's documentation.
Anthropic Claude
Caching price changes:
- Cache writes: charged at {ANTHROPIC_CACHE_WRITE_MULTIPLIER}x the price of the original input pricing
- Cache reads: charged at {ANTHROPIC_CACHE_READ_MULTIPLIER}x the price of the original input pricing
Prompt caching with Anthropic requires the use of cache_control breakpoints. There is a limit of four breakpoints, and the cache will expire within five minutes. Therefore, it is recommended to reserve the cache breakpoints for large bodies of text, such as character cards, CSV data, RAG data, book chapters, etc.
Click here to read more about Anthropic prompt caching and its limitation.
The cache_control breakpoint can only be inserted into the text part of a multipart message.
DeepSeek
Caching price changes:
- Cache writes: charged at the same price as the original input pricing
- Cache reads: charged at {DEEPSEEK_CACHE_READ_MULTIPLIER}x the price of the original input pricing
Prompt caching with DeepSeek is automated and does not require any additional configuration.
Google Gemini
Implicit Caching
Gemini 2.5 Pro and 2.5 Flash models support implicit caching, providing automatic caching similar to OpenAI. No manual setup required.
Pricing Changes:
- No cache write or storage costs.
- Cached tokens are charged at {GOOGLE_CACHE_READ_MULTIPLIER}x the original input token cost.
TTL is on average 3-5 minutes. Minimum {GOOGLE_CACHE_MIN_TOKENS_2_5_FLASH} tokens for Gemini 2.5 Flash, {GOOGLE_CACHE_MIN_TOKENS_2_5_PRO} for Pro.
Official announcement from Google
To maximize implicit cache hits, keep the initial portion of your message arrays consistent between requests.
Explicit Caching
For other Gemini models, insert cache_control breakpoints explicitly. No limit on breakpoints, but only the last is used for caching.
Cache writes: input token cost + 5 minutes storage. Cache reads: {GOOGLE_CACHE_READ_MULTIPLIER}x input cost.
TTL: 5 minutes. Minimum 4096 tokens typically.
Examples
System Message Caching
{
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a historian studying the fall of the Roman Empire. You know the following book very well:"
},
{
"type": "text",
"text": "HUGE TEXT BODY",
"cache_control": {
"type": "ephemeral"
}
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What triggered the collapse?"
}
]
}
]
}User Message Caching
{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Given the book below:"
},
{
"type": "text",
"text": "HUGE TEXT BODY",
"cache_control": {
"type": "ephemeral"
}
},
{
"type": "text",
"text": "Name all the characters in the above book"
}
]
}
]
}